I’m not very experienced with machine learning (and I’m late to the party), but I can supply my own two cents. I read the paper although I skimmed over sections that seemed to be explaining forum mafia. Apologies for this being a pretty hefty wall of text.
How they got to their benchmark (unimportant read)
Under section 3 (Machine Learning Benchmark), the paper says:
We propose the following benchmark task: Take a twenty-fold stratified shuffle split of all documents with a word count of 50 or higher. For every fold, fit a fresh instance of the pipeline on the training set. Use that instance to generate predictions for the test set. These predictions should at least be scored using the area under the precision-recall curve. The baseline score set by this paper is 0.286.
In plain English, this is saying that they:
- Took every “document” (their stand-in for a collection of posts deemed fit for the algorithm made by a single player in a single game) with 50+ words, then
- split the documents up into twenty different fragments (where “stratified shuffle split” is how exactly the data was split up; only important to signify they kept the ratio of village:mafia intact with each split) for training data and another unknown portion for test data, then
- weighted the data (because, according to the document, there’s a few factors to more consider; such as a 10000-word document being less valuable than 100 independent 100-word documents)
- trained 20 logit (logistic regression) models each on all 20 splits (with the difference being what part of the training data was used to evaluate the logit model during training), and tested all of them on the test data set aside at the beginning.
- Combined, they got an AUCPR (area under curve precision-recall) score of 0.286. I don’t think you can convert this to a percentage for how often it correctly guesses a wolf, but it gives a general guideline of how well it balances precision and recall (which, in this case, seems to be fairly poorly).
However, some of the above was only provided later in the paper.
TL;DR: They trained twenty different logistic regression models on the data and got an AUCPR score of 0.286. That doesn’t directly translate to a percentage or accuracy rating I don’t think, but it shows that the benchmark is a decently low bar.
Later, the authors claim in Table 2 they got an average precision in the range of 0.27-0.28 (where chance is 0.23). So, the model did better than chance, but it’s still a pretty poor tool for reading players. It’s unclear if this is a refined version of the benchmark model using the same logit method or simply the benchmark model itself, however.
Although, the model scored better when only analyzing >5000-word “documents” (an aggregate of everything a player has said in a game). Makes me think theoretically, as the total number of words a player posts increases, the machine approaches 100% accuracy on said player.
Some potential mafia-related takeaways
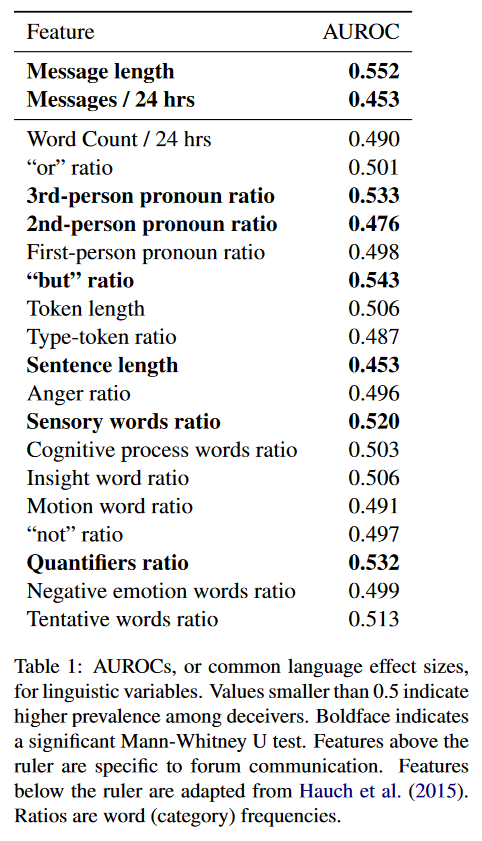
According to section 5.1 (Statistical Analysis), deception was positively correlated to post length, usage of the word “but,” and a few more; meanwhile it was negatively correlated with sentence length and post frequency. Word length and type-token ratio (total number of unique words / total number of words) didn’t correlate at all.
You can see it in Table 1 (AUROC <0.5 means more prevalent in mafia-aligned players):
Table 1 (flashbang warning)
I agree with the paper where it says
[…] the shorter posts from townsfolk may be the result of relatively unfiltered expression. Townsfolk may believe that they can broadcast any idea they come up with the moment they come up with it, since they know their thoughts are genuine. Mafia may feel the need to add more detail to their personal narrative.
However, I would take these with a grain of salt. The statistics are an aggregate of a group of presumably diverse players, and it may simply be an individual player’s mannerism to have longer sentences or to post more frequently, regardless of their alignment–however it is fairly interesting information.
As far as interpreting precision score, I believe you’re correct that it means when it guesses a player is a wolf, it’s correct 39% of the time.